AI-assisted coding is great at volume. It is less great at telling you when that volume has drifted into a problem.
A file grows past 3000 lines and suddenly it doesn't fit in the agent's context comfortably anymore. Every refactor prompt starts failing. The agent invents APIs that already exist two screens above because it never saw them. Dead code piles up because the agent keeps writing helpers that will never be called. Duplicate imports and cycles appear by accident, not by choice. Silent fan-in turns innocent modules into single points of failure. None of this shows up in a linter, and none of it shows up in a type check.
Atlante is the tool I kept wanting while I was shipping with coding agents at 11pm: a second screen that tells me what I should clean up before I ask the agent to write more code.
The workflow is intentionally simple: run Atlante, open the ranked table, click "Copy Agent Prompt", paste it into your coding agent, and ask for the next low-risk, high-value extraction.
This is the whole loop.
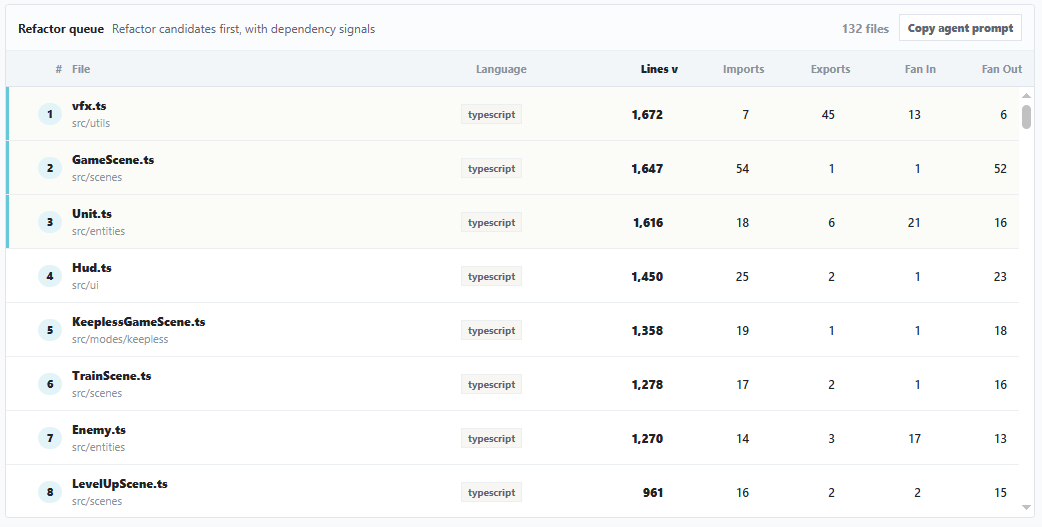
The table is the refactor queue: largest files first, with dependency signals beside each target.
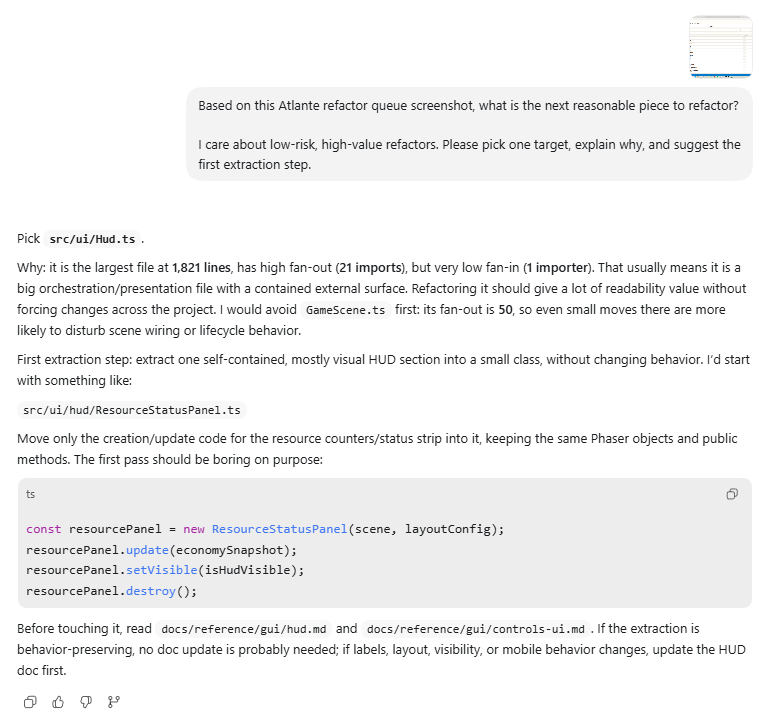
Atlante gives your coding agent the map before you ask it to refactor.
What Atlante actually does
Atlante is a VS Code extension. You open a workspace, click Analyze, and it walks the repo with Tree-sitter for JavaScript, TypeScript and Python, plus a generic parser for Java, C#, Go, Rust, Kotlin, Swift, Ruby and PHP. The result is a static inventory of every file, every import, every export, every symbol, plus fan-in and fan-out per file.
That inventory becomes two views. The table is the everyday product.
The table is a refactor queue. One row per file, ranked by the signals that matter when an agent has been adding too much code: lines, imports, exports, fan-in, and fan-out. Start with the largest files, then look at the hub files. Click a row and a drawer opens with symbols, imports broken down between resolved, external and unresolved, and the list of files that depend on it.
The point is not to declare a file "bad". The point is to pick a reasonable first target.
Each row has a "Copy Agent Prompt" action. One click and you get a structured triage prompt with your top files and their dependency signals, ready to paste into Claude Code, Cursor, or any other coding agent. The prompt asks the agent to pick the next low-risk extraction, explain why, and say what not to touch. No screenshots needed.
The second is a constellation. The internal dependency graph rendered as nodes clustered by top-level folder, with a focus mode that dims everything not connected to the selected file. The table tells you what to refactor. The graph tells you what to leave alone. A utility file with 30 incoming edges and zero outgoing lights up immediately, and that is exactly the kind of file you do not refactor casually, even if it is small.
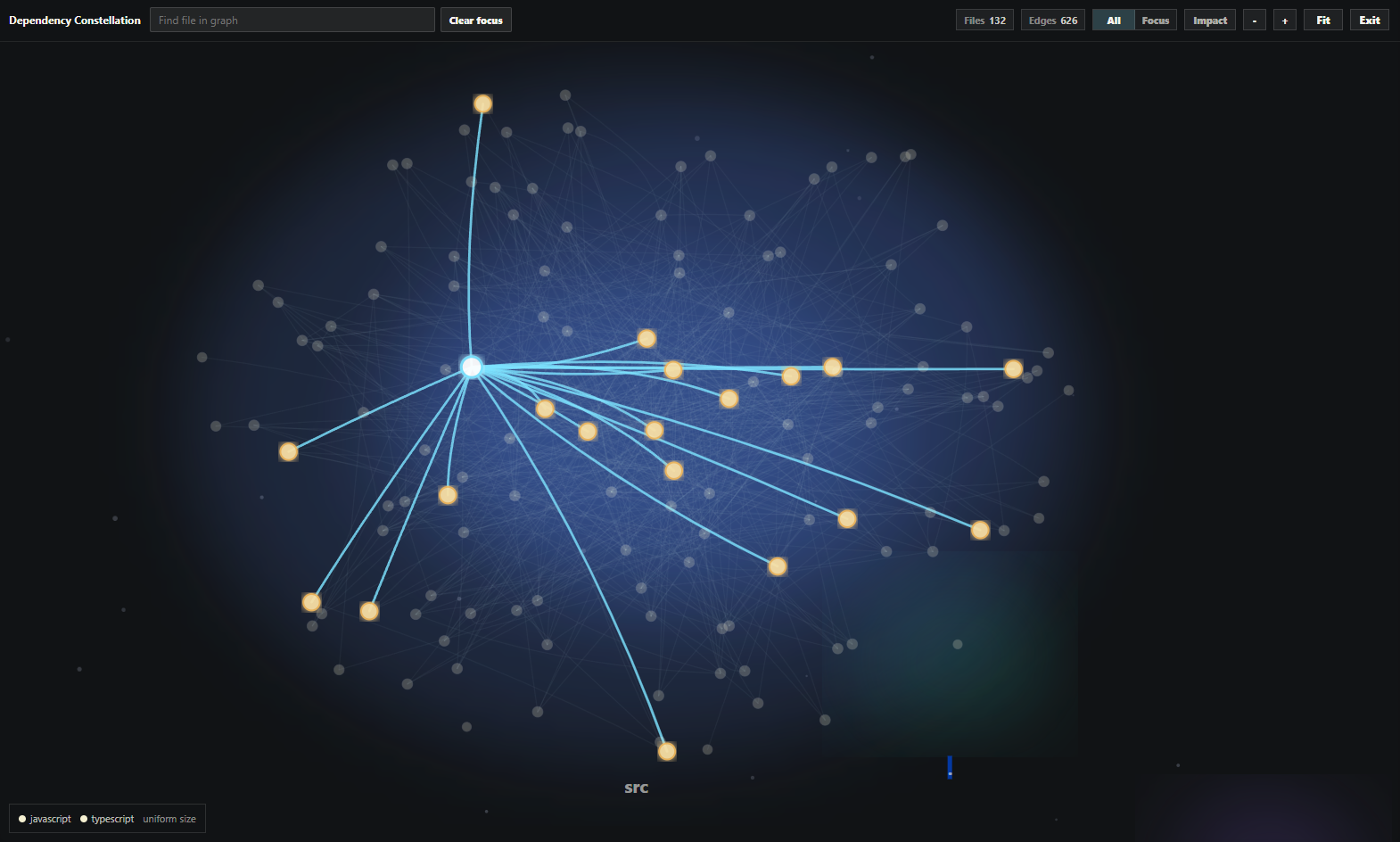
The graph is the shape of the repo. The table is where the next refactor starts.
Results persist under .atlante/ as stable, diff-friendly JSON. You can commit it, ignore it, or pipe it somewhere. That is your data, on your disk.
Three principles, in order
Deterministic. Same input, same output. Always. This is what lets you trust the verdict, pin it in CI, or use it in a pre-commit hook. An LLM answer that changes every run cannot do that job.
Local. Nothing leaves the machine. No account, no upload, no telemetry on your code. That is what makes Atlante usable on private, proprietary, regulated repos, which is where most of the interesting code actually lives.
Prescriptive. Every output is actionable. Not "here is a graph, good luck" but "this file is too big, this one is a hub, this cycle lives between these four modules". The current table already gives you natural refactor targets. The next layer, already scoped, turns the inventory into named refactor flags: god-file, giant-function, hub-file, file-cycle, dead-export, and a handful of structural smells.
If a feature would break one of those three principles, it probably does not belong in Atlante.
What it isn't
It is not a linter. Linters look at one line. Atlante looks at the shape of the whole repo.
It is not a type checker. Type checkers care about types, not about which module has quietly become a single point of failure.
It is not an AI code reviewer. There is no model in the loop. That is the point.
It is not a general dependency visualizer. That category is saturated. Atlante is something narrower and, I think, more useful: a refactor queue sitting on top of the inventory, telling you where to start next.
Why now
The visualizers have been around for a decade. The category that did not exist before is triage after the agent has written a bunch of code. Claude Code, Cursor, Aider and tools like them produce a lot of code and very little structural context. Someone has to look at the shape of what came out, and the person best placed to do it is the human who asked for it, in the five minutes between two prompts.
Atlante is the second mental screen for that moment.
What's next
The current build ships the inventory, the table, the drawer, the graph, and the multi-project library. The next milestone is the diagnostics layer: deterministic rules that turn the inventory into explicit refactor flags, a Health column in the table, a "Needs refactor" quick filter, and a badge on the activity bar so the signal comes to you instead of the other way around. The full plan lives in the repo under docs/todo/diagnostics.md.
Try it
Atlante is open source under MIT. If any of this sounds useful, install it and point it at the messiest repo you own.
Feedback, especially the uncomfortable kind, is welcome.